python request官方文档
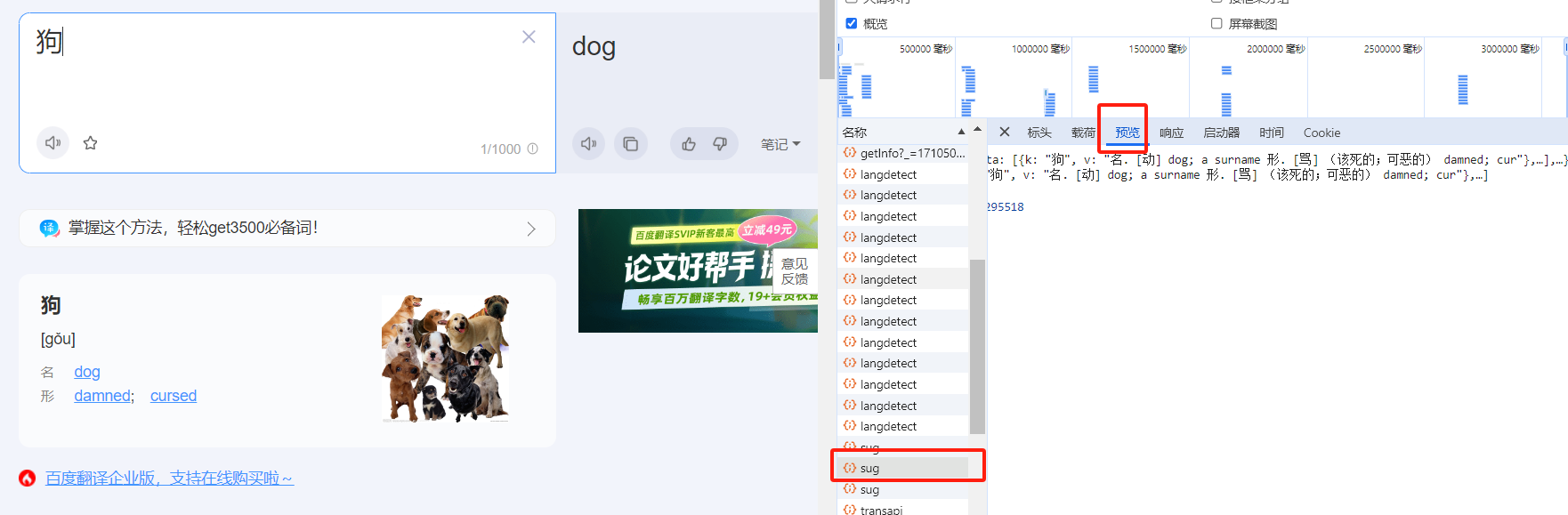
python爬虫 爬百度翻译 在翻译网站随便输入个中文翻译,然后按F12
知道带正确返回的值,然后查看标头,就能知道url了
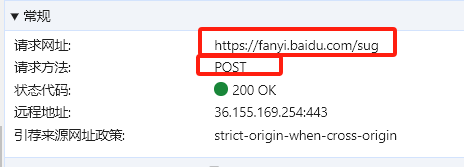
然后也要注意请求方法,对于参数我们可以去payload(载荷)看
之前找错了,那个表单有个sign和ts(时间戳),这两个是会变化的值,在写data的时候不容易弄,发现sug里有个更简单的表单数据,就用这个了,下面是代码.
import requestsimport timewhile True : word = input ("请输入你需要翻译的中文(q-退出):" ) if word == 'q' : break else : data = { 'kw' :word, } resp = requests.post("https://fanyi.baidu.com/sug" ,data) json_data = resp.json() print (json_data) data_list = json_data['data' ] for data in data_list: print (data['k' ] + ": " + data['v' ])
爬美女图片 import requests url = 'https://cdn.seovx.com/?mom=302' resp = requests.get(url=url) #print(resp.text) with open('./tu.png', mode='wb') as f: f.write(resp.content) #print('保存成功')
爬视频 url='https://api.linhun.vip/api/Littlesistervideo?type=json&apiKey=05961127134-89951501711-d6a79dfe896' resp = requests.get(url=url) print (resp.json())url2 = resp.json()['video' ] content = requests.get(url=url2).content with open ('girl.mp4' , mode='wb' ) as f: f.write(content)
要注意,里面有个apiKey是需要手动获取的,是为了防止恶意使用,然后这种别的媒体的形式,需要获取字节码,然后保存到相应格式的文件中。
实验 1.访问 新浪微博网页
查看网页源代码,可以发现这些新闻链接是通过js生成的,所以我们需要查看js页面
*2.分析 *页面
找到get请求返回的页面,查看信息,可以发现链接和标题都在里面,所以我们需要提取的页面是这个
*3.提取 *页面
首先很明显是一个json格式,需要切片,转换格式,然后根据实际情况提取信息即可
import json import requests url = “https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=2&r=0.3009011709274978&callback=jQuery111202890527579006905_1716863975570&_=1716863975571" # *替换为实际的页面链接 * response = requests.get(url) reply = json.loads(response.text[46:-14]) #print(len(reply[‘result’][‘data’])) for i in reply[‘result’][‘data’]: *#print(i) * print(i[“url”]) print(i[“title”])
这里就不每个页面都提取了,如果需要提取,可以改成以下格式
for page_num in range(1, num): url = "https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page={}&r=0.3009011709274978&callback=jQuery111202890527579006905_1716863975570&_=1716863975571".format(page_num) print(url)
可以看看title和相应网页里面的标题是否一致
可以看到标题和链接都是对应的,下面就是进入相应的网页提取文本和配图了
**4.**提取正文和配图
进入目标页面,查看网页源代码,找到网页确定正文的逻辑
可以看到正文都是在id为artibody的div下,且每段文字都由p标签包裹,所以我们可以通过确定这两个元素来获取正文内容,需要注意的是当div为null时,是没有find_all方法的,我们需要先判断div元素是否存在。
*#* *判断* *<div>* *元素是否存在 * if div_element is not None: p_tags = div_element.find_all("p") *#* *遍历每个* *<p>* *标签,获取内容 * content = "\n".join([p.text for p in p_tags]) *#* *提取配图链接 * img_tags = div_element.find_all("img") image_urls = [f"https:{img['src']}" for img in img_tags] *#* *创建新闻文件夹 * news_dir = os.path.join(save_dir, title) os.makedirs(news_dir, exist_ok=True) *#* *保存新闻标题和正文到文件 * with open(os.path.join(news_dir, "content.txt"), "w", encoding="utf-8") as f: f.write(content)
可以看到获取到了相应的正文内容,下面就是获取img了,同样的原理,获取相应的img标签即可
*#* *提取配图链接 * img_tags = div_element.find_all("img") for img_tag in img_tags: image_url="https:" +img_tag.get("src") print(image_url) *#* *下载配图 * image_response = requests.get(image_url) image_name = os.path.basename(image_url) image_path = os.path.join("news_data", image_name) with open(image_path, "wb") as f: f.write(image_response.content)
**5.**保存成对应的文件夹,并做异常处理
在img处添加try:catch
*#* *下载配图并保存到文件 * for i, image_url in enumerate(image_urls): try: response = requests.get(image_url) image_name = f"image_{i+1}.jpg" image_path = os.path.join(news_dir, image_name) with open(image_path, "wb") as f: f.write(response.content) except requests.exceptions.InvalidURL: print(f"Invalid URL: {image_url}")
完整代码:
import jsonimport osimport requestsfrom bs4 import BeautifulSoupsave_dir = "news_data" os.makedirs(save_dir, exist_ok=True ) url = "https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=2&r=0.3009011709274978&callback=jQuery111202890527579006905_1716863975570&_=1716863975571" response = requests.get(url) reply = json.loads(response.text[46 :-14 ]) links = [] for i in reply['result' ]['data' ]: links.append(i["url" ]) for link in links: response = requests.get(link) response.encoding = "utf-8" news_soup = BeautifulSoup(response.text, "html.parser" ) title = news_soup.find("h1" ).text div_element = news_soup.find("div" , id ="artibody" ) if div_element is not None : p_tags = div_element.find_all("p" ) content = "\n" .join([p.text for p in p_tags]) img_tags = div_element.find_all("img" ) image_urls = [f"https:{img['src' ]} " for img in img_tags] news_dir = os.path.join(save_dir, title) os.makedirs(news_dir, exist_ok=True ) with open (os.path.join(news_dir, "content.txt" ), "w" , encoding="utf-8" ) as f: f.write(content) for i, image_url in enumerate (image_urls): try : response = requests.get(image_url) image_name = f"image_{i+1 } .jpg" image_path = os.path.join(news_dir, image_name) with open (image_path, "wb" ) as f: f.write(response.content) except requests.exceptions.InvalidURL: print (f"Invalid URL: {image_url} " ) print (f"Saved news: {title} " ) else : print (f"No content found for: {title} " )
Xpath解析 Xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言可用来在XML和HTML文档中对元素和属性进行遍历。简单来说,我们的数据是超文本数据,想要获取超文本数据里面的内容,就要按照一定规则来进行数据的获取,这种规则就叫做Xpath语法。
XPath语法
层级 / 直接子级 // 跳级
属性 @ 属性访问
函数 contains()、text()等
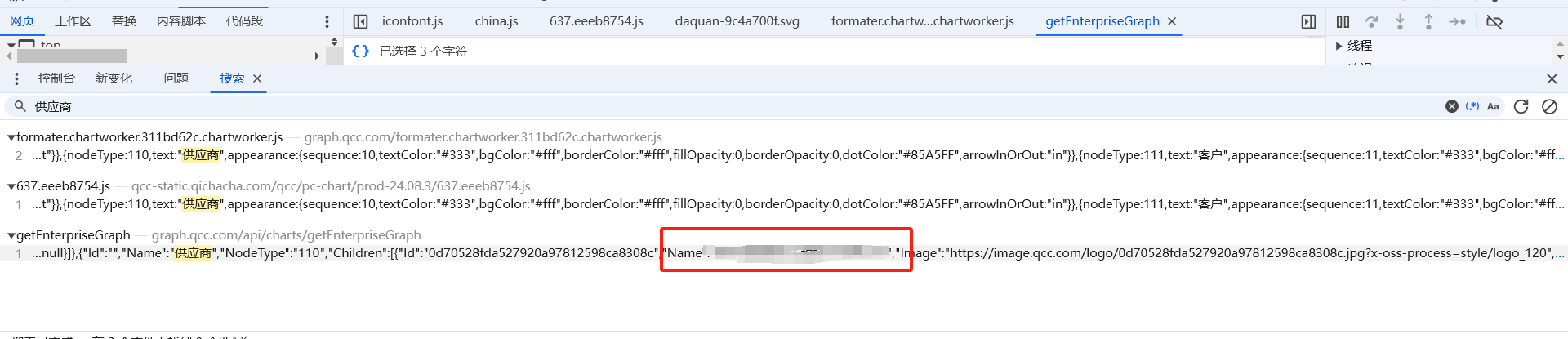
企查查供应商爬取 首先,因为需要收集供应商信息,除了寻标宝等,在企查查中也有供应商的图,但数量比较大,且查看源码发现是动态生成的,下面开始测试,以某公司为例
第一步:打开源代码寻找相关js文件
右键源代码/来源里的文件,全局搜索关键词:供应商
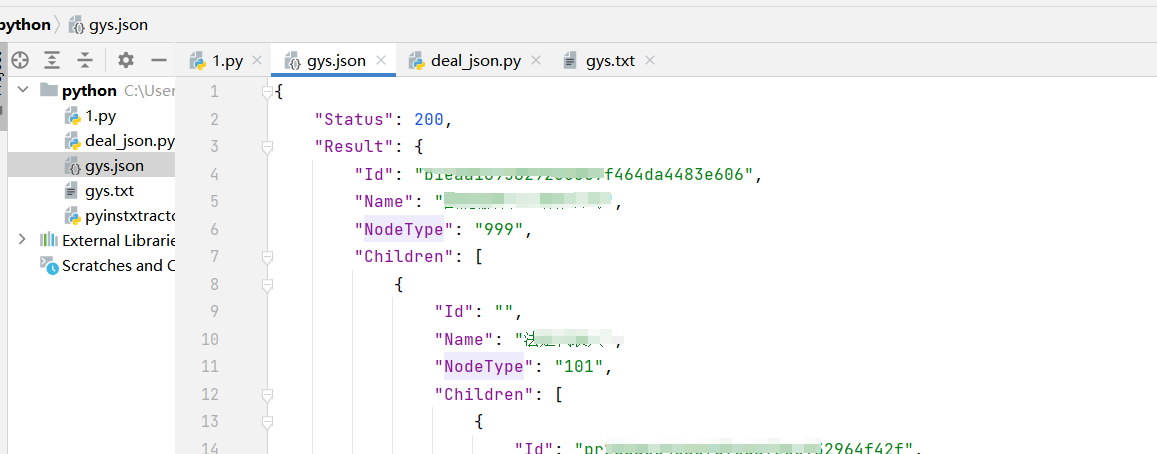
第二部:确定文件数据格式,保存为json文件
第三步:判断层级,确定长度是否与图一致,图里是500,然后就是根据长度保存
import jsonwith open ("gys.json" , 'r' ,encoding='utf-8' ) as f: data = json.load(f) print (json.dumps(data, indent=4 ))print (len (data["Result" ]["Children" ][5 ]["Children" ]))with open ("gys.txt" , "w" ) as f: for i in range (500 ): f.write(data["Result" ]["Children" ][5 ]["Children" ][i]["Name" ] + "\n" )
比较容易没什么问题
字符串独有功能
大小写
开头 结尾
切割
连接
替换
是否是数字
去除空白
公共功能
练习 获取文件后缀,输出指定文件后缀的文件名
import ospath = "F:\CodeSpace\PythonWorkSpace\pythonProject" filename_list = os.listdir(path) for i in filename_list: name = i.rsplit('.' , maxsplit=1 ) end = name[-1 ] if end == "txt" : print (i)
Python爬取前程无忧招聘数据
import pandasfrom DrissionPage import ChromiumOptions""" 环境使用: python3.8 Pycharm """ """ 模块使用: DrissionPage 自动化 csv pandas pyecharts 可视化 """ """ # 设置电脑内浏览器去可执行文件路径 # 运行一下就可以注释掉了 # DrissionPage 自动化模块 """ from DrissionPage import ChromiumPageimport jsonimport csvf = open ('data.csv' ,mode='w' ,encoding='gbk' ,newline='' ) csv_writer = csv.DictWriter(f, fieldnames={ '职位' , '薪资' , '城市' , '区域' , '经验' , '学历' , '公司' , '公司领域' , '公司性质' , '公司规模' , '公司详情页' , }) csv_writer.writeheader() dp = ChromiumPage() dp.get("https://we.51job.com/pc/search?jobArea=000000&keyword=python&searchType=2&keywordType=" ) for page in range (1 ,51 ): print (f"正在采集弟{page} 页的数据" ) dp.scroll.to_bottom() divs = dp.eles('css:.joblist-item' ) for div in divs: info = div.ele('css:.joblist-item-job' ).attr('sensorsdata' ) json_data = json.loads(info) c_name = div.ele('css:.cname' ).text.strip() c_link = div.ele('css:.cname' ).attr('href' ) c_info = [i.text for i in div.eles('css:.dc' )] if len (c_info) == 3 : c_num = c_info[-1 ] else : c_num = '未知' AreaInfo = json_data['jobArea' ].split('·' ) if len (AreaInfo) == 2 : city = AreaInfo[0 ] area = AreaInfo[1 ] else : city = AreaInfo[0 ] area = '未知' """ 字典中最后有逗号和没逗号是有区别的 有逗号会一个一个对应 没逗号则只取第一个 """ dit = { '职位' : json_data['jobTitle' ], '薪资' : json_data['jobSalary' ], '城市' : city, '区域' : area, '经验' : json_data['jobYear' ], '学历' : json_data['jobDegree' ], '公司' : c_name, '公司领域' : c_info[0 ], '公司性质' : c_info[1 ], '公司规模' : c_num, '公司详情页' : c_link, } csv_writer.writerow(dit) print (dit) dp.ele('css:.el-icon-arrow-right' ).click()